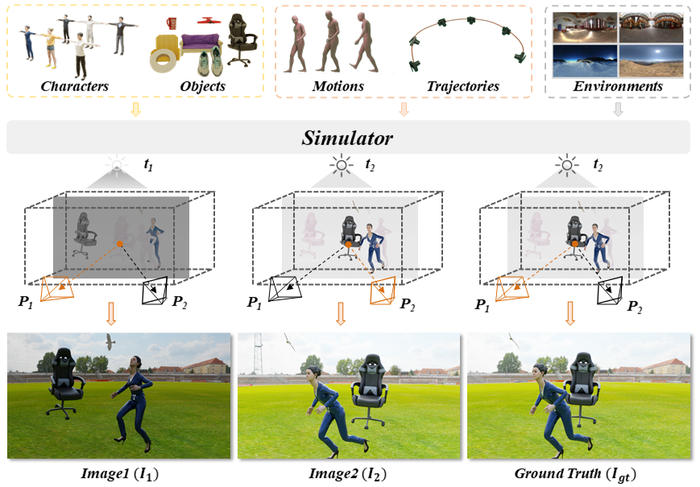
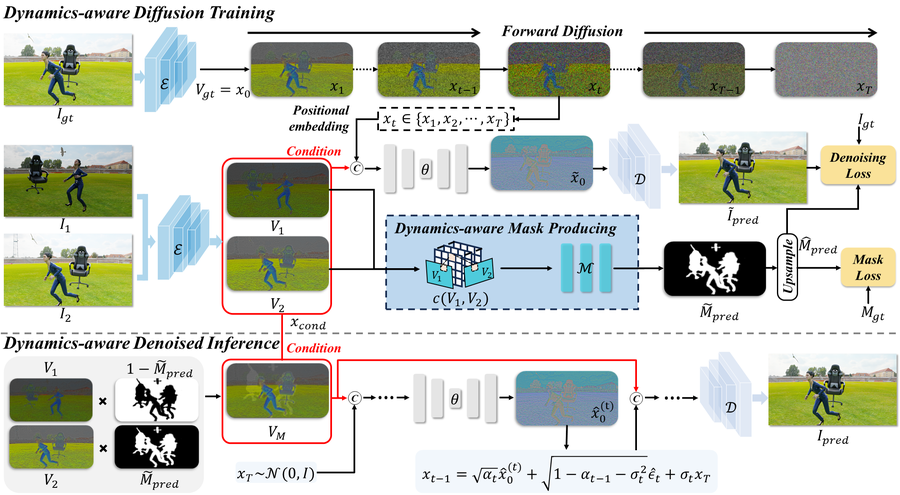
🔍 Motivation
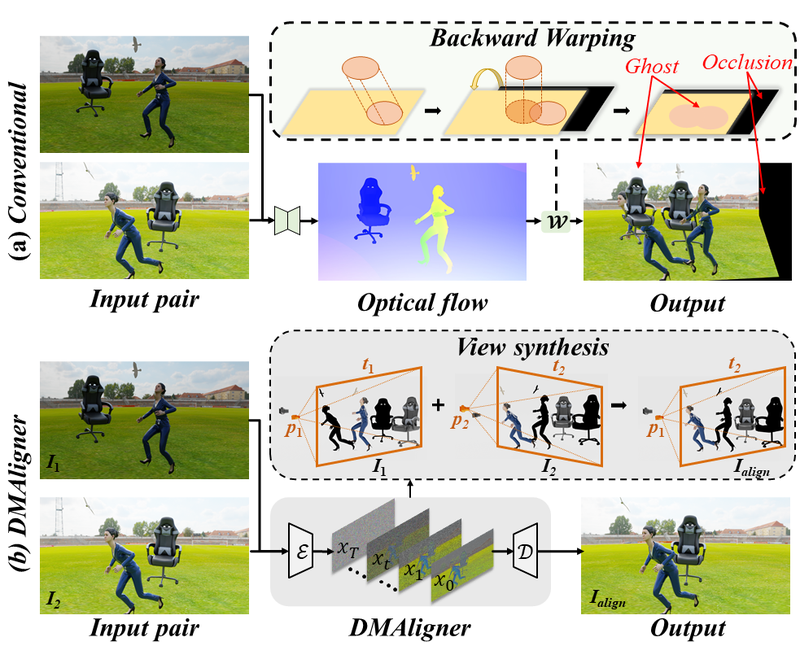
Classic alignment
Optical flow + warping moves pixels from one frame to another, but occlusions and disocclusions often lead to ghosting artifacts.
Our perspective
DMAligner synthesizes the aligned view directly, allowing the model to fill occluded regions and reconstruct dynamic content.